
中日韩越统一表意文字(CJKV Unified Ideographs),目的是要把分别来自中文、日文、韩文中,本质相同、形状一样或稍异的表意文字(主要为汉字,但也有仿汉字如日本国字、韩国独有汉字)于ISO 10646及Unicode标准内赋予相同编码。越南文后来亦加入此计划,所以亦有“CJKV”的称呼。Unicode亦开始收录其仿汉字-喃字。
精选百科
本文由作者推荐
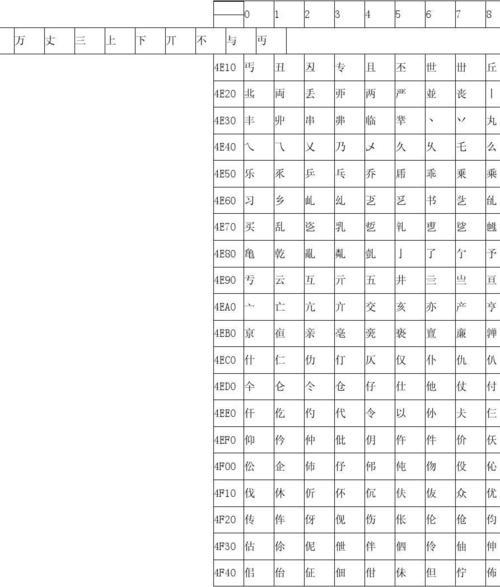
中日韩越统一表意文字
中日韩越统一表意文字
中文名
中日韩越统一表意文字
别名
Unicode、统一码、中日韩统一表意文字
外文名
CJKV Unified Ideographs
文字
中文、日文、韩文、越文
国家
中日韩越
时间
1980年
概况
中日韩越统一表意文字
(英语:CJKV Unified Ideographs
),旧称中日韩统一表意文字
(英语:CJKUnified Ideographs
),也称统一汉字
(英语:Unihan
),目的是要把分别来自中文、日文、韩文、越文、壮文中,对于相同起源、本义相同、形状一样或稍异的表意文字主要为汉字,但也有仿汉字如:方块壮字、日文汉字(かんじ / kanji)、韩文汉字(한자 / hanja)、越南的喃字(Chữ Nôm)与越文汉字[汉字/Hán Tự,在越南也称作儒字(儒/Chữ Nho)],应赋予其在ISO 10646及统一码标准中有相同编码。此计划原本只包含中文、日文及韩文中所使用的汉字,是以旧称中日韩统一表意文字(CJK)。后来,此计划加入了越文的喃字,所以合称中日韩越统一表意文字(CJKV)。历史沿革
1978 年,日本基于ISO 2022,制订了全世界最早的汉字编码 JIS C6226。1980年代,中国大陆、中国台湾、韩国则各自制订了自己的规范。这些规范彼此之关并无关联。若要在一份文件中同时使用,则要以脱序字符的方式来交换。
1980 年,日本的国立国会图书馆的高桥德太郎以图书学的观点指出,一个统一的东亚汉字编码系统是有必要的。同年,中国台湾制定了三字节的中文信息交换码。偶然的是,这是第一个期望可以一致处理中国大陆、日本、中国台湾汉字的编码。之后,美国的国会图书馆采用了此规格,并另外命名为东亚编码字符(EastAsia Coded Character,EACC,ANSI/NISOZ39.64)。
1984年,ISO 的文字编码委员会(ISO/TC97/SC2)决议制订出一套编码规格(ISO10646),是以交换文字集的方式来统一处理世界的文字。并成立了工作小组(ISO/TC97/SC 2/ WG 2)。这个编码一开始的构想是采用16位,而对于日本及中国等国的汉字编码则原封不动地加入。但若如此,中国当时所制订的编码都无法加入,因而反对。并于1989年,提出了各国的汉字统合集合(HanCharacter Collection,HCC)的构想。
1990年完成了 ISO10646 的初版草案(DIS10646)。汉字使用32 位来表示。并将各国的汉字编码原封不动地加入。但中国认为,若各国各自为汉字编码,将不利于统一处理汉字,因而反对。为了日后关于汉字编码的讨论及方针能顺利进行,并呼吁WG 2 特别设置了中日韩联合研究小组(CJK-JRG,JointResearch Group,为表意文字小组的前身),以持续讨论。
另一方面,1987年,全录的 JoeBecker 和Lee Collins 开发了统合处理全世界所有文字的统一码。1989年发表了统一码概要。基本为 16 位。于是,中、日、韩文字统合了。基本方针为以16 位处理所有文字。 1990年,完成了基于此方针的最终草案。来年1991年1月,大致同意此方案的企业成立了统一码联盟。中、日、韩中类似的汉字使用约二万多个字。为了未来扩充,保留了三万个汉字以供其它用途。
1991年,各国希望能以一致的方式处理文字,如统一码这般,因而否决了ISO/IEC 10646 的初版草案。基于中国与统一码联盟的提议,ISO10646 和统一码成立了中日韩联合研究小组。中日韩联合研究小组将基于各国的汉字编码,独自订定规范、制作ISO 10646 和统一码的统一汉字编码。年尾,完成了UnifiedRepertoire and Ordering (URO)。
1992年,URO 加入 ISO10646 的第二版。但是,发现了一些缺失,之后进行了修正。
1993年5月,正式制订了最初的中日韩统一表意文字,位于U+4E00–U+9FFF 这个区域,共20,902 个字。一个月后,制订了统一码1.1。
1999年,依据 ISO/IEC10646 的第17 个修正案(Amendment17)订定了扩充区 A ,于U+3400–U+4DFF 加入了6,582 个字。
2001年,依据 ISO/IEC10646-2,新增了扩充区B ,有 42,711 字。位于U+20000–U+2A6FF。但因在短时间内增加了大量的汉字,导致产生了许多重复的字形。
2005年,依据 ISO/IEC10646:2003 的第1 个修正案(Amendment1),基本多文种平面增加了 U+9FA6 到 U+9FBB 等 22 个汉字。
2009年,统一码 5.2 扩充区 C 增加了U+2A700-U+2B734 和U+9FC4~U+9FCB。
2010年,统一码 6.0 扩充区 D 增加了U+2B740-U+2B81F。
2012年,1字增加 U+9FCC。
字源
最初期统一汉字
最初期的统一汉字(20,902字)字源来自以下字集:
中国大陆的G源
G0:GB 2312-80:6,763字
G1:GB 12345-90:2,352字(含58个中国香港字和2个吏读字,不包括和G0重覆的字)
G3:GB 7589-87:7,237字
G5:GB 7590-87:7,039字
G7:现代汉语通用字表:642(G0, 1, 3, 5, 8未包括的字)
G8:GB 8565-89:290字(G0, 1, 3, 5未包括的字)
中国台湾的T源
T1:CNS 11643-1986第一字面:5,401+9字(含9个计量用汉字)
T2:CNS 11643-1986第二字面:7,650字
TE:CNS 11643-1986第十四字面:6,319+239+10(含239个CCCII特字和10个XCCS特字)
日本的J源
J1:JIS X 0208-90:6,335+1字
J2:JIS X 0212-90:5,801字
韩国的K源
K0:KS C 5601-87:4,888字(含268个重见字)
K1:KS C 5657-91:2,856字
以上的来源字集会实施字源分离原则。
另外还有:ANSI Z39.64-1989(EACC)、Big5、CCCII第一面、GB 12052-89、JEF、中国大陆电报码、中国台湾电报码、Xerox Chinese。这些来源字集不会实施字源分离原则。
很多人以为20,902统一汉字中来自中国台湾的只是Big5的一万三千多字,其实不然.
扩展A区
扩展A区包含有6,582个新的汉字,位置在 U+3400—U+4DB5。相比起最初期统一汉字,扩展A区多了来自多个来自中国大陆、中国台湾、新加坡等汉字。
这6千多个汉字分别从以下字典或字集中取得:中国大陆 《康熙字典》5357字(独有1892字)
《汉语大字典》5888字(独有339字)
G3:GB 7589-87 繁体字:2391字
G5:GB 7590-87 繁体字:1226字
G7:120字 GS:新加坡汉字226字 中国台湾 T3:CNS 11643-1992 第三字面(原本为CNS 11643-1986第十四字面)新加入字元
T4:CNS 11643-1992 第四字面
T5:CNS 11643-1992 第五字面
T6:CNS 11643-1992 第六字面
T7:CNS 11643-1992 第七字面
TF:CNS 11643-1992 第十五字面
日本 JA: Unified Japanese IT Vendors Contemporary Ideographs, 1993
南韩 K2:PKS C 5700-1:1994 K3:PKS C 5700-2:1994
越南 V0:TCVN 5773:1993 V1:TCVN 6056:1995
扩展B区
扩展B区包含有42,711个新的汉字,位置在 U+20000—U+2A6D6。根据ISO/IEC JTC1/SC2/WG2/IRG N777号文件,这四万多个汉字分别从以下字典或字集中取得:
CNS 11643的第4平面到第15平面所收录的30,177个汉字;
在《汉语大字典》中出现的28,914个未收录汉字;
在《康熙字典》中出现的18,486个未收录汉字(包括一个在补遗篇出现汉字);
在北朝鲜的国家标准所收录的5,642个汉字;
在越南的国家标准所收录的4,232个字喃;
HKSCS中出现的1,081个未收录汉字;
《汉语大词典》中出现的553个未收录汉字;
《四库全书》中出现的522个未收录汉字;
日本工业标准的JIS X 0213第3平面及第4平面的302个未收录汉字;
1980年代版本的《辞海》中出现的247个未收录汉字;
大韩民国PKS 5700-3:1998中出现的166个未收录汉字;
《中国大百科全书》中出现的86个未收录汉字;
《辞源》中出现的66个未收录汉字;
北大方正排版系统中出现的65个未收录汉字;
这堆汉字中重复的汉字有不少,所以经过整理之后,总数实际上只有42,711个汉字。
另外,在 U+2F800—U+2FA1D 的位置,放了542个来自中国台湾的兼容汉字。
Unicode 4.1汉字
为使 Unicode 向下兼容 GB 18030 和中国香港增补字符集(HKSCS)的所有汉字,而扩展C区又迟迟未能出笼,在 Unicode 4.1 版中引进了14个中国香港增补字符集的用字和8个 GB 18030 用字。该22字被编于 U+9FA6—U+9FBB 的位置。
另外,在 U+FA70—U+FAD9 的位置,放了106个来自北朝鲜的兼容汉字。
扩展C区按计划,中日韩统一表意文字扩展C区将收录4,251个汉字,包括来自中国大陆、中国澳门、中国台湾、日本、越南等尚未被编码的汉字。这些汉字预计会收录在下一版的 Unicode 版本中,位置在 U+2A6E0—U+2B77A。
字源分离原则
字源分离原则(Source Separation Rule)是整理中日韩统一表意文字的基础。
由于CJK各地字型多有微妙的差异,如“户”字的第一笔,中国台湾作撇、中国大陆作点、日本作横,这种程度的差异,理想上是整并为一个字为佳。然而,从之前各种受挫之文字整并计划的经验得知,整合字集与现行通用字集(Big5或国标码)等无法一一对应,是推行整合字集的最大阻碍。
例如,日本的JIS标准同时收录了“剣”字与“剑”字,原本JIS文件里这两个字可以并存,但采用整合字集后反而变成同一个字,会造成使用上的困扰。于是,字源分离原则因而诞生。
字源分离原则是指,在上述所列出之各种字源里,若有任何字集同时收了两种以上的文字字形,则在Unicode中日韩统一表意文字中,也同时收录这些字。这样一来,现行的各种原有字集与Unicode汉字可以一一对应。
由于Unicode中日韩统一表意文字的主要诉求,就是能大幅减少Unicode收录汉字字数,同时尊重各地的习惯字形。但字源分离原则则破坏了“只对字,而不对字形”编码之原则,亦遭受不少批评。
已统一的汉字原则上ISO 10646只对字(Character),而非字形(Glyph)编码。同一字各地可使用自己的标准写法。下例中使用HTML标示同一编码的字在不同地区中的写法(但只是我的电脑提供的字型,未必代表该地区的标准写法)。
扩展C区
于2009年10月发布的Unicode 5.2涵盖了扩展C区,共收录4,149个汉字,包括来自中国大陆、中国澳门、中国台湾、日本、越南等尚未被编码的汉字。位置在 U+2A700—U+2B734。
扩展D区
扩充区D包含的都是所谓的「急用汉字」,合共222个新汉字,于2010年下旬发布的Unicode6.0中,编码范围为 U+2B740 至 U+2B81F(实际有字符为 U+2B740 至 U+2B81D)。
扩展D区原本计划放置扩展C区未收录的16,000多个汉字,但在2007年5月,中国台湾撤消了6,545个第二部分字集内私用汉字,不再使用字,原因是那些人名用字的拥有人或已去世或已移居外地,此后扩展D区缩减到大约10,000字左右。由于各种阻碍,协议先把数量较少,又急切要收录的汉字提交出来,就是「急用汉字」,以便和统一码6.0.0版一起发表。提出的急用汉字只有二百二十二字(本来有二百二十三字,但中国大陆撤回其中一字)。现在文字小组把第二部分字集延后到扩充E区。
汉字
有些字只是同一字在不同地区的写法,理应统一,但因为字源分离原则而只好分开编码。值得注意的是字源分离原则由扩展A集 (Extension A) 开始已没有使用,原因是CNS中有太多字形非常接近,按 Unicode 标准应该统一的字。这些字只有第一个会编入正式字集(包括Extension A,B,C) 中,其余的编入位于第二辅助平面的表意文字补充兼容区 (Compatibility Ideographs Supplement) 中。
以下是所有摘自ISO/IEC JTC1/SC2/WG2字源分离原则文件之中有的字。
| Unicode | 字 | Unicode | 字 | Unicode | 字 |
| U+4E1F | 丢 | U+4E22 | 丢 | ||
| U+4E48 | 么 | U+5E7A | 幺 | ||
| U+4E89 | 争 | U+722D | 争 | ||
| U+4EDE | 仞 | U+4EED | 仭 | ||
| U+4F75 | 并 | U+5002 | 倂 |
问题
扩展B区使用了辅助平面来摆放汉字,以致不少字处理软件都不能支持。例如,Microsoft Office2000 或之前的版本,即使计算机拥有扩展B区汉字字体,也只会显示两个方格。
另外,因扩展B区在整理上有缺陷,收录了以下5个本来应该与其他汉字统一的字:
· U+20457 =U+34A8 㒨
· U+2420E =U+3DB7 㶷
· U+27144 =U+8641 虁
· U+23515 =U+204F2
· U+249E9 =U+249BC
而在 WG2 N1155 文件中,亦列出了152对可考虑统一的汉字。
中日韩越统一表意文字相关的文章

脑动脉瘤是常见血管性疾病,是自发性蛛网膜下腔出血最常见的原因。脑动脉瘤可见于任何年龄,但50~69岁患者居多,约占总发病率的2/3。动脉瘤病因不明,其发生是多种因素、多种机制并存导致。未破裂动脉瘤可无症状,较大的动脉瘤可压迫邻近脑组织或脑神经出现相应的局灶症状,如癫痫、偏瘫、失语、视力和视野障碍等。
也称“颅神经”。是从脑发出左右成对的神经,属于周围神经系统。人的脑神经共12对:Ⅰ嗅神经、Ⅱ视神经、Ⅲ动眼神经、Ⅳ滑车神经、Ⅴ三叉神经、Ⅵ外展神经、Ⅶ面神经、Ⅷ位听神经、Ⅸ舌咽神经、Ⅹ迷走神经、Ⅺ副神经、Ⅻ舌下神经。它们主要分布于头面部,其中迷走神经还分布到胸腹腔内脏器官。在这12对脑神经中,第Ⅰ、
蚜虫(英文名:Aphid),是球蚜总科(Adelgoidea)和蚜总科(Aphidoidea)昆虫的统称,又称腻虫、密虫,隶属于节肢动物门昆虫纲半翅目,包括球蚜科、根瘤蚜科、纩蚜科、平翅绵蚜科、扁蚜科、瘿绵蚜科、群蚜科、毛管蚜科、斑蚜科、毛蚜科、大蚜科、短痣蚜科和蚜科。蚜虫体长0.5~7.5mm,大
法鲁克一世(拉丁文转写:Fārūq),全名穆罕默德·法鲁克(Muhammad Fārūq),第二任埃及和苏丹国王,努比亚、科尔多凡和达尔富尔的统治者(1936年至1952年在任)。

尚可名片
这家伙太懒了,什么都没写!
作者

